![图片[1]-谷歌惊艳研究界!全新小巧 Gemma AI 模型震撼登场,本地智能计算轻松实现!-零度博客](https://www.freedidi.com/wp-content/uploads/2024/02/hero-image.webp)
近期,谷歌一直在积极推动各类Gemini AI模型,而今天,他们专为特定用户群体推出了一个更为精简的新型号。这款全新的模型被命名为Gemma,主要面向那些希望利用本地模型而非通过云服务访问人工智能的研究人员。
据谷歌在一篇博客文章中透露,Gemma是由其位于英国的DeepMind团队与其他团队共同开发的。与其兄弟Gemini相比,Gemma确实共享一些“技术和基础设施组件”。该模型有两种特定型号可供选择:Gemma 2B和Gemma 7B。研究人员可以访问“经过预训练和指导调整的Gemma模型”,这些模型可以在本地台式机或笔记本电脑上运行,同时也支持在云端运行,且已经过优化,可以在Nvidia GPU和Google Cloud TPU(张量处理单元)上运行。
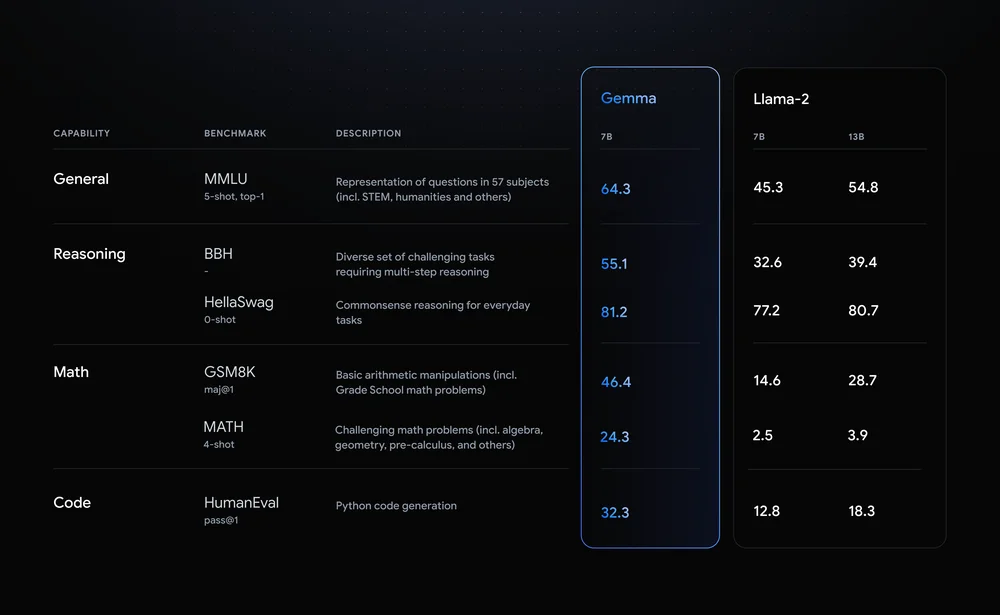
虽然Gemma 2B和7B模型在技术上相对较小,但谷歌声称它们胜过了“在关键基准上显著更大”的其他大型语言模型(LLM),包括Meta的Llama 2。
目前,谷歌已经在其Kaggle研究人员平台上免费提供Gemma,并且还可作为Colab笔记本的免费使用。对于未使用Google Cloud的用户,可以通过300美元的免费积分来访问Gemma,同时,研究人员还有购买最多500,000美元积分以通过Google Cloud使用该模型的选项。
值得一提的是,本月初,谷歌宣布将其Bard聊天机器人更名为Gemini,并推出了适用于Android的Gemini移动应用程序,以及通过iOS设备的Google搜索应用程序提供对AI模型的访问。同时,谷歌还发布了Gemini Advanced,这是其最先进的型号,每月价格为19.99美元。
而在二月下旬,公司还发布了Gemini 1.5 Pro,据称比1.0 Pro和1.0 Ultra都更为强大,尽管目前尚未公布发布日期的具体消息。
Gemma是一系列轻量级、最先进的开放式模型,采用与创建Gemini模型相同的研究和技术而构建。 Gemma 由 Google DeepMind 和 Google 的其他团队开发,其灵感来自 Gemini,其名称反映了拉丁语gemma,意思是“宝石”。除了模型权重之外,我们还发布了工具来支持开发人员创新、促进协作并指导负责任地使用 Gemma 模型。
Gemma 从今天开始在全球发售。以下是需要了解的关键细节:
- 我们发布了两种尺寸的模型配重:Gemma 2B 和 Gemma 7B。每个尺寸都发布了经过预训练和指令调整的变体。
- 新的Responsible Generative AI 工具包为使用 Gemma 创建更安全的 AI 应用程序提供了指导和基本工具。
- 我们通过原生Keras 3.0提供跨所有主要框架的推理和监督微调 (SFT) 工具链:JAX、PyTorch 和 TensorFlow 。
- 即用型Colab和Kaggle 笔记本,以及与Hugging Face、MaxText、NVIDIA NeMo和TensorRT-LLM等流行工具的集成,让您可以轻松开始使用 Gemma。
- 预先训练和指令调整的 Gemma 模型可以在您的笔记本电脑、工作站或 Google Cloud 上运行,并可轻松部署在Vertex AI和Google Kubernetes Engine (GKE) 上。
- 跨多个 AI 硬件平台的优化可确保行业领先的性能,包括NVIDIA GPU和Google Cloud TPU。
- 使用条款允许所有组织(无论规模大小)负责任地进行商业使用和分发。
小型且最先进的性能
Gemma 模型与Gemini共享技术和基础设施组件,Gemini 是我们当今广泛使用的最大、功能最强大的 AI 模型。与其他开放式型号相比,这使得 Gemma 2B 和 7B 能够在其尺寸范围内实现同类最佳的性能。 Gemma 模型能够直接在开发人员笔记本电脑或台式计算机上运行。值得注意的是,Gemma 在关键基准上超越了更大的模型,同时遵守我们安全和负责任的输出的严格标准。有关性能、数据集组成和建模方法的详细信息,请参阅技术报告。
对设计负责
Gemma 的设计以我们的人工智能原则为核心。为了使 Gemma 预训练模型安全可靠,我们使用自动化技术从训练集中过滤掉某些个人信息和其他敏感数据。此外,我们还根据人类反馈(RLHF)进行了广泛的微调和强化学习,以使我们的指令调整模型与负责任的行为保持一致。为了了解和降低 Gemma 模型的风险状况,我们进行了稳健的评估,包括手动红队、自动对抗测试以及危险活动模型能力评估。我们的模型卡中概述了这些评估。1
我们还与 Gemma 一起发布了新的Responsible Generative AI Toolkit,以帮助开发人员和研究人员优先构建安全且负责任的 AI 应用程序。该工具包包括:
- 安全分类:我们提供了一种新颖的方法,可以用最少的示例构建强大的安全分类器。
- 调试:模型调试工具可帮助您调查 Gemma 的行为并解决潜在问题。
- 指南:您可以根据 Google 在开发和部署大型语言模型方面的经验,获取模型构建者的最佳实践。
跨框架、工具和硬件进行优化
您可以根据自己的数据微调 Gemma 模型,以适应特定的应用程序需求,例如摘要或检索增强生成 (RAG)。 Gemma 支持多种工具和系统:
- 多框架工具:带上您最喜欢的框架,以及跨多框架 Keras 3.0、本机 PyTorch、JAX 和 Hugging Face Transformers 进行推理和微调的参考实现。
- 跨设备兼容性: Gemma 模型可以跨流行的设备类型运行,包括笔记本电脑、台式机、物联网、移动设备和云,从而实现广泛的 AI 功能。
- 尖端硬件平台:我们与 NVIDIA 合作,针对 NVIDIA GPU 优化 Gemma,从数据中心到云端再到本地 RTX AI PC,确保行业领先的性能并与尖端技术集成。
- 针对 Google Cloud 进行了优化: Vertex AI 提供了广泛的 MLOps 工具集,其中包含一系列调整选项以及使用内置推理优化的一键部署。完全托管的 Vertex AI 工具或自我管理的 GKE 提供高级自定义功能,包括从任一平台跨 GPU、TPU 和 CPU 部署到经济高效的基础设施。